Big Spatial Data – Your day has come
Despite all the buzz that surrounds the term “big data,” we hear surprisingly little about “big spatial data.” Of the top ten results from an Incognito Google search for “Big Spatial Data,” only two results are from 2015 and only one – “GIS Tools for Hadoop by ESRI” – attempts to present a solution. Despite apparently being the only tool available, there were only 25 commits on GitHub in 2015. There are only 43 results in a Google Scholar search for 2015. From a demand perspective, Google Trends shows us that Big Spatial Data is not what people are looking for, either.
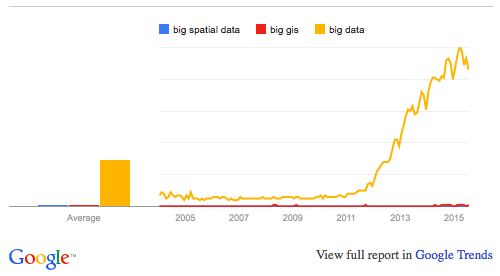
The Value of Big Spatial Data
Are we to conclude that “Big Spatial Data” is an irrelevant topic? Is it perhaps no different than other big data? I would argue no.
Spatial data and spatio-temporal data are tremendously valuable. They can help ships, planes, and UAVs move more safely. They help organizations operate more efficiently and companies market more effectively, and they make mobile applications more functional. In short, spatio-temporal data have the potential to make our lives better, if we can build the analytics to harness them. Before we can build these analytics however, we need a platform to store and access Big Spatial Data. Everything from mobile apps to sophisticated analytics need fast, efficient access to select portions of data for computation or visualization.
After we’ve spent the last two decades digitizing almost everything, we have mounds of data stored in a multitude of storage systems. Simply figuring out how to handle all of this data is a tremendous challenge. If there is any question, refer back to the first chart to see how much interest there is in “Big Data.” Perhaps tackling the complexities of Big Spatial Data, and in particular big spatio-temporal data, has been kicked down the road. The time to address these challenges is now.
Examples of Big Spatial Data
Mobile apps, cars, GPS, UAVs, ships, airplanes, and IoT devices are generating more spatial data by the day. Consider the following example: A single track from an aircraft reporting its location every second (as is typically done using Automatic Dependent Surveillance – Broadcast (ADS-B) systems) for a 2.5 hour flight generates 9,000 points and the National Air Traffic Controllers Association estimates there are 87,000 flights per day in the US. Roughly figured, that’s 285 billion points per year (all flights will be required to use ADS-B in 2020). Furthermore, that assumes that each point is collected only once, when the reality is that many sensors have overlapping coverage, likely making this volume much higher.
There are nearly a billion tweets every day and many of them are geolocated. Now think about Instagram, Facebook, Google Maps, Uber, and the dozens of other applications that capture your location using your mobile phone. All of these tools are generating huge streams of spatial data. Few would argue that these data streams lack value, but if we cannot store them in such a way that they can be accessed and manipulated quickly, what is the point of collecting them at all?
Challenges with Big Spatial Data
Storing and querying spatio-temporal data in general is different than most other types of data. To begin with, there are several different types of spatial data. Vector data are comprised of points, lines, and polygons. Raster data includes imagery data. Different applications require different kinds of queries. Some may only wish to extract data within a specific time and area. But what if our data is track data and the track crosses through my search window, but none of the reported points occur within that window? Should that track be included in the query results? Most spatial data have spatial correlation. Does that impact your modeling assumptions when building an analytic?
The challenges of spatial data have been enumerated many times before; and honestly, there are many excellent solutions for handling these data. However, these solutions all have their limitations. For example, PostGIS is one of my favorite tools for storing spatial data, but eventually it reaches a capacity limit. The point here is that spatio-temporal data need special treatment, and many of the solutions that have been offered to address big data do not sufficiently support big spatial data. A solution for spatio-temporal data in a big data environment is sorely needed.
The most logical starting point is to leverage a distributed database to create an analog to the spatial versions of relational databases – that is to say, an “HBaseGIS” or “AccumuloGIS”. The inherent structure of these systems, however, presents a new challenge. Most of these databases have a single index for a datum. Unlike relational databases where you can simply add indexes to as many columns as you like, NoSQL databases have a single primary index which has to support most of your queries. Naturally, spatio-temporal data are most frequently queried by a space-time window. Thus, to quickly query spatio-temporal data, we have to collapse three dimensions of data down into a single index.
While these challenges make managing spatio-temporal data more complex, none of them are insurmountable. In fact, this is the first article in a series where I will discuss various aspects of the GeoMesa, is an open-source suite of tools, hosted in Eclipse’s LocationTech Working group, that enable you to store, index, and query big spatio-temporal data using Apache HBase, Apache Accumulo, or Google Cloud Bigtable.
Conclusion
It is safe to say that Big Spatial Data is an important topic for discussion, and it certainly warrants more attention than a few outdated links on a Google Search. To do my part, I will write a series of posts about Big Spatial Data, GeoMesa, Spatial Analytics, and open-source technology. I’ll conclude by asking: What are your Big Spatial Data challenges?
To keep up-to-date with the latest work going on at GA-CCRi, follow us on Twitter at @ccr_inc.