Deep Learning and Ontology Development
Ontologies are widely used for representing and reasoning about semantic content in a structured way. However, manual ontology construction is a subtle and time-consuming process that often yields mixed results. Hand-crafted ontologies tend to be inflexible and inordinately complex, which limits their usefulness and makes cross-domain alignment painfully difficult. Practitioners are faced with several daunting challenges, including efficient generation of robust type systems, multi-modal fusion, and improvements to the semantic quality and concision of knowledge graphs while preserving their logical structure.
Recent advances in machine learning, particularly involving deep neural networks, have the potential to help mitigate these issues with ontology development and alignment while enhancing and automating aspects of implementation and expansion. We at GA-CCRi have done a lot of work in some of these areas, especially:
- Knowledge discovery, federated search, and SPARQL queries
- Data fusion, mapping, alignment, and aggregation
- Natural Language Processing (NLP) alignment
Project features that we have implemented in these areas have included:
- Alignment within a semantic vector space of diverse data modalities, including text, imagery, and Resource Description Format (RDF) triples, using mapping transformations between domains
- Scalable semantic indexing and discovery in the fused data space, including geospatial and SPARQL query capabilities
- Customization of deep learning content models for text, overhead imagery, and full-motion video
- Detection of inconsistencies and anomalies across data sources
- Automatic suggestions for missing metadata values
- Extraction, disambiguation, and resolution of types, topics, and named entities from unstructured text
Let’s take a closer look at some of this work.
Deep Content Models
In the past decade, deep learning has generated much excitement in the machine learning community and beyond. Compared with older models that require more manual intervention and produce inferior results, deep neural networks now boast state-of-the-art performance in a wide variety of fields, including image recognition, natural language processing, machine translation, knowledge base completion, and reinforcement learning. Many deep learning algorithms are fundamentally feature learning algorithms that represent data within multi-dimensional vector spaces, also known as embedding spaces. For example, convolutional neural networks learn high-level features that encode the content of images, while word2vec (developed at Google but publicly available) learns compact vectors that encapsulate the distributional meanings of words. These representations enable robust data fusion across domains and support downstream modeling, which facilitates the expansion and alignment of existing ontologies.
The foundation of our modeling approach is to produce high-quality data representations that are directly derived from the content without requiring extensive manual engineering of features. The advantages are twofold: the models capture the rich semantics of the data within each domain or modality, and they also also produce compact encodings that are amenable to fusion and additional modeling.
Over the past several years, GA-CCRi has researched and developed a variety of novel software solutions for several customers. As a part of these efforts, we have applied convolutional neural networks (CNNs) to both text and overhead imagery. CNNs are well-known for their ability to successfully learn features across multiple layers of increasing abstraction, and they are currently the state-of-the-art models for several machine learning tasks, especially scene understanding and speech recognition.
More recently, GA-CCRi has also done work for one customer involving caption generation for full-motion video. Following the latest results in the scientific literature, our approach applies a CNN to each frame of the video, incorporating information about the optical flow, and then feeds the representation to a long short-term memory (LSTM) recurrent neural network. The LSTM takes sequential data as input and generates responses by combining the most recent input with long-range history, producing sentence captions for video.

Data Fusion
Embedding models seek to address the challenge of disparate (big) data directly by using a deep learning process to leverage all inputs into a single learned numeric signature per entity. This learning step has the benefit of both compressing potentially large, raw inputs to a fixed size for use in bandwidth-constrained environments as well as making diverse input data equally accessible to the full gamut of conventional machine learning techniques.
Embedding spaces are also amenable to modeling explicit transformations between them. This approach provides a powerful tool for domain transfer and data fusion. Examples of such mappings include:
- Fusion of disparate text sources
- Fusion of disparate knowledge graphs
- Fusion of overhead imagery with structured geospatial data
- Fusion of full-motion video with text
- Machine translation between languages
The ontology alignment problem can also be viewed through the lens of machine translation. Given a small amount of training data, it is possible to learn mappings between different ontologies or map them into a shared semantic space. By using the automatically-generated ontology as the target space, we can expand and merge manually-crafted ontologies while taking advantage of predefined structures. This process also enables detection of inconsistencies and anomalies among the various schema.
GA-CCRi has leveraged this neural network fusion technology for two recent projects. For one of these, we have prototyped a system that learns representation vectors for entities in a large knowledge graph to enable fusion so that a data model can be maintained efficiently across distributed cloud nodes. Our approach to enabling this is to learn content vectors for each entity using a multitask learning approach. The core model to this approach learns from RDF statements: subject-predicate-object triples about entities in a large database. The model learns by first assigning a randomly initialized content vector to each entity and predicate and then using the TransE model to predict whether each statement is actually a true statement in the knowledge base or not.
Fusion of the learned knowledge across the machines is done only at the model level: model weight updates are shared between the two machines, but none of the training data is shared. The cost of sharing the model weights is insignificant relative to sharing of the raw data.
The other neural network fusion project leverages multi-modal datasets provided by the customer. Within this project, GA-CCRi developed the capability to address both the scalability and distribution of image processing on large remote sensing data sets. A portion of this effort focused on the exploitation of overhead imagery for data fusion.
Originally, this framework was born out of the need to extract image-specific information content in support of a larger data fusion effort. The targeted fusion effort aimed to leverage embedding models to relate disparate data sources (for example, imagery, text, geographic, and temporal sensor data) in the face of expanding data volumes.
Knowledge Discovery and Federated Search
Fused embedding spaces are also useful for answering questions that are directly relevant to analysts and domain experts. GA-CCRi has developed scalable search tools over embedding spaces for various modalities supporting free text, geospatial, and SPARQL queries, among others. We can also provide supporting feedback evidence to the user in order to increase their confidence in the model. For example, if a document is returned that contains no terms matching the query, the model automatically displays the closest semantic matches between important terms in the document and the query.
GA-CCRi’s Large Scale Semantic Discovery with Neural Content Models project addresses problems associated with manual content curation for information retrieval: inconsistencies in tag assignment, inaccurate tagging, scalability problems, and federated search across fused data sets. By replacing this manual metadata assignment with the use of deep neural networks that analyze both content and metadata and represent their semantics using embedded vector models, the system can perform tasks such as part-of-speech tagging, word-sense disambiguation, and entity extraction. The use of CNNs adds the ability to automatically generate such metadata from images, and the use of embedding vectors for this metadata means that metadata from images, text, and other media can be combined for easier cross-media research.
To further improve the metadata used to drive analyst information retrieval, these techniques enable the inference of missing metadata values, the identification of anomalous tags, and the extraction and categorization of named entities from text as additional metadata. The implementation of the system on cloud-based servers provides scalability of storage and processing to go with the greater scalability of automated metadata assignment over manual metadata assignment.
Natural Language Processing and Mapping
A distinguishing feature of semantic vector spaces is the ability to automate the grouping together of entities by similarity in a continuous way and the modeling of various relations as transformations of the underlying space. In particular, the nearest-neighbor relation provides a latent encoding of various subtle and fine-grained attributes. For example, the vector for Putin lies near the vectors for related entities such as Russia, Moscow, and Kremlin. Moreover, simple algebraic operations on the vector space can be used to complete analogies to some extent. For example, the difference between the vectors for Russia and Putin is similar to the difference between the vectors for Syria and Assad. These processes can be used to uncover unexpected and surprising correlations that are not explicitly contained in the source data such as latent power structures within organizations. For semantic representations of text and graph, GA-CCRi has implemented a version of Google’s well-known SkipGram algorithm. This model enables us to represent the meanings of words, as well as nodes in a graph—for example, documents linked to metadata, or RDF data derived from geospatial sources.
Embedding vectors are also convenient for training additional supervised models, e.g. in order to rank anomalous entities relative to a given criterion or to suggest a value for a missing item along with a confidence score. GA-CCRi has developed such capabilities, including knowledge base augmentation, metadata suggestion, and entity categorization. In recent work, GA-CCRi has also been developing a capability for automated creation of latent type systems using embeddings, geared toward text-mining tasks such as topic extraction, type inference, and entity disambiguation and resolution. In particular, we are able to suggest new classes to extend an ontology based on new data.
Ontologies generated by neural language models have the advantage of containing both discrete and continuous representations, which allows them to efficiently encode semantic signatures of entities and relationships in a way that can feed downstream logical processes.
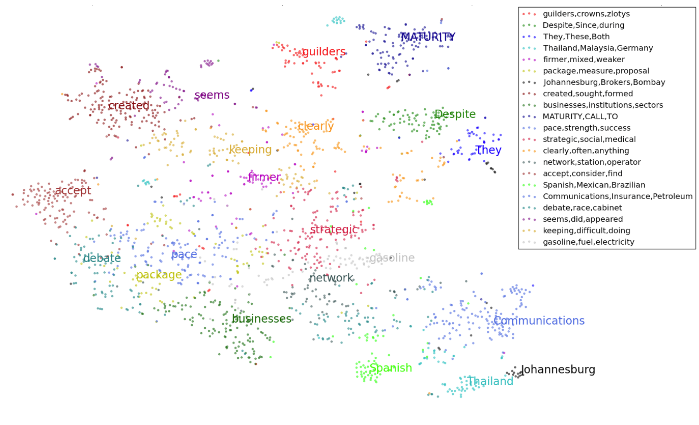
The image above shows an automatic type clustering of words. Each cluster centroid is labeled with the closest word in embedding space. At this high level, we apparently see the separation of nouns, verbs, adjectives, and proper nouns, along with some finer topical distinctions. By repeating this process with higher-resolution clusterings, we obtain a latent hierarchy of subtypes such as the way the set of proper nouns contains the set of location names, which in turn contains names of countries and cities, and so forth. This same technique will be very useful in automated ontology generation.
In order to fully exploit the information in this hierarchy, it is critical to disambiguate terms according to the contexts in which they occur. For example, the image below shows disambiguation of mentions of the term Jordan across documents. Note that the model is able to distinguish different broad entities (for example, Jordan the basketball player vs. Jordan the country) but also different topical usages of the same entity such as political vs. economic mentions of the country Jordan.
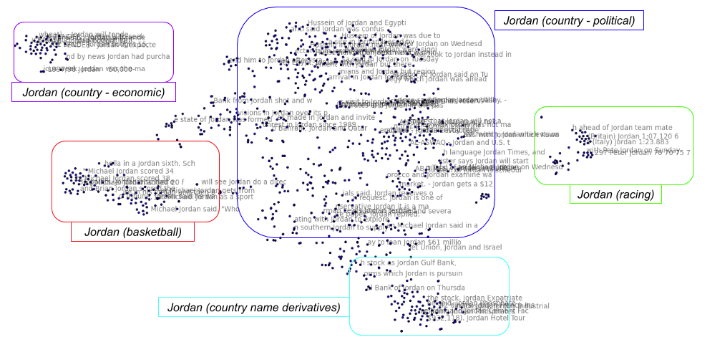
This ability to generate ontologies is a good example of how GA-CCRi often applies different kinds of neural networks to work together to solve a larger problem. In this case, the data fusion, knowledge discovery, federated search, natural language processing, and disambiguation abilities can all work together to create an ontology that is more than just labeled clusters of similar words. These techniques draw on latent semantics of the terms in a document collection to create a more meaningful ontology that can help users navigate that collections better and get more value from those documents.