Which Armstrong?
In my last post, I described how we used Elias, an exploratory analysis tool for large-scale information extractions, to look at which (person,location) pairs are mentioned the most together, and then extended the analysis to distinguish how those entities are comentioned. Today, I’d like to have a look at how Elias can help with entity recognition, in a similar manner.
Across a corpus of practically any size, it is likely that more than one entity will be referred to with the same name. This may happen most frequently when a shortened name for an entity is used after a longer name earlier in the same document. For example, we use Elias to tabulate the number of mentions for all people in Wikipedia, and focus here on the top 20 entities containing the string “Armstrong”:
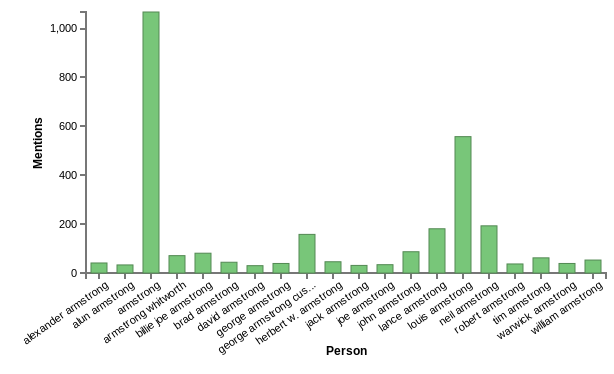
The most mentioned “Armstrong” is the generic last name. This is not surprising, as after “Lance Armstrong” is mentioned in an article, for example, it would not be uncommon to simply use “Armstrong” later in the article.
What we’d like to do is see if we can distinguish the various Armstrongs based on the context in which they are mentioned. To accomplish this, we use Elias to pull out all documents which mention an Armstrong, and then use Mahout to perform topic modeling on those documents. Then, for each Armstrong, we average the topic vectors of the containing documents to obtain a topic distribution for the entity.
However, we have a problem, as we expect “Armstrong” to refer to many different individuals, as described above. In our Pig script with which we are directing our exploration (including the Elias query and the Mahout tasks), let us distinguish a mention of an Armstrong as “unknown” if the entity name is simply “Armstrong,” and “known” otherwise. While not strictly legitimate, we then assume any known Armstrong has a unique name used across all documents, while an unknown Armstrong can be any known Armstrong each time it appears. So Document A’s “Lance Armstrong” is the same as Document B’s “Lance Armstrong”, but the “Armstrong” of Document C is treated as a separate entity from the “Armstrong” of Document D.
Having split our entities up in this manner, and joined across documents to obtain a topic distribution, we have effectively embedded all the Armstrongs into a multi-dimensional vector space (dimensions equal to the number of chosen topics, in our case 100). Here, we can cluster the entities, hopefully placing some unknown entities in the same cluster as a known entity, and thus distinguishing them. To visualize the result, we use Mahout’s dimensionality reduction to project to two dimensions, and distinguish clusters by shape and color:

The diagram above shows the most mentioned Armstrongs (just “known” Armstrongs for now), and clicking around we find that each has been placed in a unique cluster (though some color/shape pairs are duplicated). Let’s focus on two of the most popular Armstrongs: Lance and Neil. In particular, let’s look at all the Armstrongs, known or unknown, which were put in the same cluster with these two. Elias’s filtering capabilities make this easy, and we obtain the following:
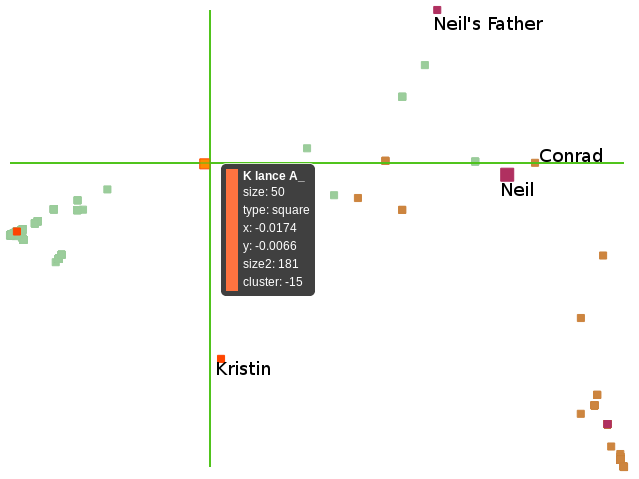
In this diagram, Lance’s cluster is the orange dots on the left (unknown entities in greenish), and Neil’s cluster is the purple dots on the right (known entities in brownish). The other known entities in Lance’s cluster are Kristin Armstrong (either an ex-wife, or olympic cyclist) and “post-Armstrong”, while the others in Neil’s cluster are “Neil Alden Armstrong” (his full name) and “Stephen Armstrong” (his father). To easily check if the unknown Armstrongs are properly clustered, in the tooltips (not shown) we include any known Armstrongs in the same document as the unknown Armstrong mention. Hovering over the points, we seem to have done a pretty good job. This actually includes points which didn’t have any known Armstrongs in the same document, like the brown point just above and to the right of Neil Armstrong’s point. This reference is on Pete Conrad‘s page (he’s another astronaut), and the reference is comparing the two explorer’s initial statements after walking on the moon.
Most, though certainly not all, Natural Language Processing tools focus on sentence level extractions. These clearly need additional post-processing to be moderately useful, and Elias provides a scalable way to perform such analyses, or simply look at the results.